publications
Publications in reversed chronological order. * indicates equal contribution
2026

2025







2024
- Under Review
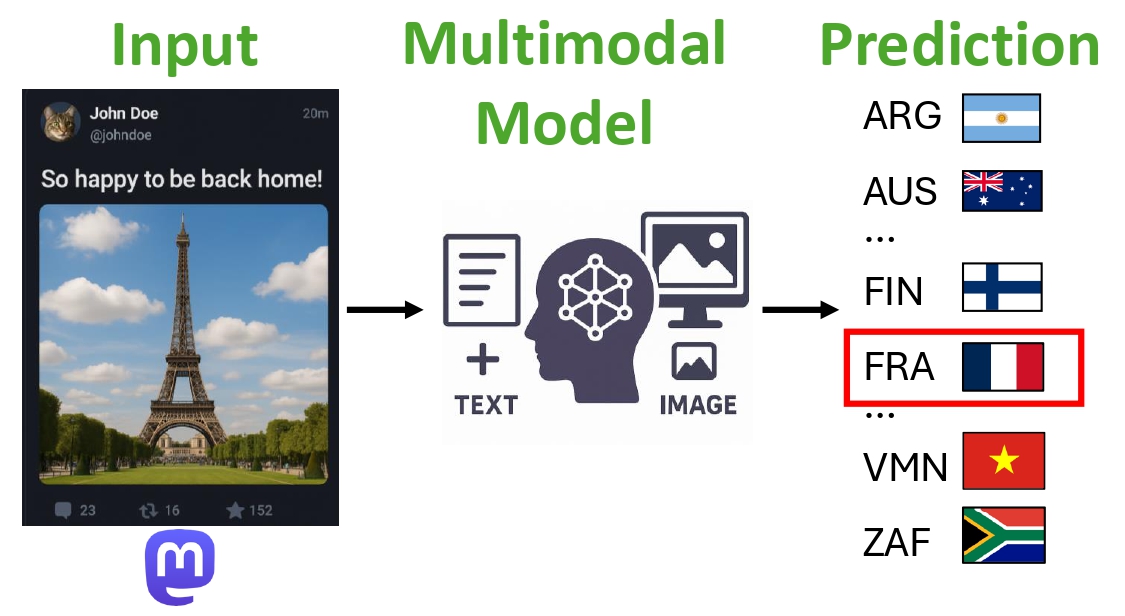 Latent Geographies: Joint Embeddings of Text and Visual Cues for Social Media GeolocationOct 2024
Latent Geographies: Joint Embeddings of Text and Visual Cues for Social Media GeolocationOct 2024 - You don’t need a personality test to know these models are unreliable: Assessing the Reliability of Large Language Models on Psychometric InstrumentsIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Jun 2024


